Eksempel gjennomsnitt.
La et utvalg av størrelse n trekkes ut for å studere den generelle populasjonen med hensyn til den kvantitative egenskapen X.
Prøvegjennomsnittet er det aritmetiske gjennomsnittet av egenskapen til prøven.
![]()
Prøveavvik.
For å observere spredningen av et kvantitativt attributt for prøveverdier rundt middelverdien, introduseres en oppsummerende karakteristikk - prøvevariansen.
Prøvevariansen er det aritmetiske gjennomsnittet av kvadratene av avviket til de observerte verdiene til en funksjon fra deres gjennomsnittsverdi.
Hvis alle verdiene til prøvefunksjonen er forskjellige, da

Korrigert varians.
Utvalgsvariansen er et skjevt estimat av den generelle variansen, dvs. den matematiske forventningen til utvalgsvariansen er ikke lik den estimerte generelle variansen, men er lik
![]()
For å korrigere prøvevariansen er det nok å multiplisere den med en brøk
Eksempelkorrelasjonskoeffisient finnes i henhold til formelen

hvor er prøvestandardavvikene til og .
Prøvekorrelasjonskoeffisienten viser stramheten til det lineære forholdet mellom og : jo nærmere enhet, jo sterkere er det lineære forholdet mellom og .
23. En polygon av frekvenser er en brutt linje, hvis segmenter forbinder punktene. For å bygge en polygon av frekvenser, på abscisse-aksen, legg av alternativene, og på ordinataksen, de tilsvarende frekvensene og koble punktene med rette linjesegmenter.
Polygonen til relative frekvenser er konstruert på lignende måte, bortsett fra at relative frekvenser er plottet på y-aksen.
Et histogram av frekvenser er en trinnformet figur som består av rektangler, hvis basis er delintervaller med lengde h, og høydene er lik forholdet. For å bygge et frekvenshistogram, plottes delintervaller på x-aksen, og segmenter tegnes over dem parallelt med x-aksen i en avstand (høyde). Arealet av det i-te rektangelet er lik - summen av frekvensene til varianten av i-o-intervallet, derfor er arealet til frekvenshistogrammet lik summen av alle frekvenser, dvs. prøvestørrelse.


Empirisk distribusjonsfunksjon
hvor n x- antall prøveverdier mindre enn x; n- prøvestørrelse.
22La oss definere de grunnleggende begrepene for matematisk statistikk
.Grunnleggende begreper i matematisk statistikk. Generell populasjon og utvalg. Variasjonsserier, statistiske serier. Gruppert utvalg. Grupperte statistiske serier. Frekvens polygon. Prøvefordelingsfunksjon og histogram.
Befolkning- alt settet med tilgjengelige objekter.
Prøve- et sett med objekter tilfeldig valgt fra den generelle befolkningen.
En sekvens av alternativer skrevet i stigende rekkefølge kalles variasjon side ved side, og listen over alternativer og deres tilsvarende frekvenser eller relative frekvenser - statistiske serier:te valgt fra den generelle befolkningen.
Polygon frekvenser kalles en brutt linje, hvis segmenter forbinder punktene.
frekvenshistogram kalt en trinnformet figur som består av rektangler, hvis basis er delintervaller med lengde h, og høydene er lik forholdet.
Eksempel (empirisk) distribusjonsfunksjon kall opp funksjonen F*(x), som bestemmer for hver verdi X relativ hyppighet av hendelsen X< x.
Hvis et eller annet kontinuerlig trekk undersøkes, kan variasjonsserien bestå av svært et stort antall tall. I dette tilfellet er det mer praktisk å bruke gruppert utvalg. For å få det, er intervallet, som inneholder alle de observerte verdiene til funksjonen, delt inn i flere like dellengdeintervaller h, og finn deretter for hvert delintervall n i er summen av frekvensene til varianten som falt inn i Jeg-th intervall.
20. Loven om store tall skal ikke forstås som en generell lov knyttet til store tall. Loven om store tall er et generalisert navn for flere teoremer, hvorfra det følger at med en ubegrenset økning i antall forsøk, har gjennomsnittsverdiene en tendens til noen konstanter.
Disse inkluderer Chebyshev og Bernoulli teoremene. Chebyshevs teorem er den mest generelle loven om store tall.
Grunnlaget for beviset for teoremer, forent med begrepet "lov om store tall", er Chebyshevs ulikhet, som fastslår sannsynligheten for avvik fra dens matematiske forventning:
![]()
19 Pearson-fordeling (kikvadrat) - fordeling tilfeldig variabel
hvor tilfeldige variabler X1, X2,..., Xn er uavhengige og har samme fordeling N(0,1). I dette tilfellet vil antall termer, dvs. n, kalles "antall frihetsgrader" for kjikvadratfordelingen.
Kikvadratfordelingen brukes til å estimere variansen (ved å bruke et konfidensintervall), i testing av hypoteser om samsvar, homogenitet, uavhengighet,
Fordeling t Student er fordelingen av en tilfeldig variabel
hvor tilfeldige variabler U og X uavhengig, U har en standard normalfordeling N(0,1) og X– distribusjon chi – firkantet med n grader av frihet. Hvori n kalles "antall frihetsgrader" for studentens distribusjon.
Den brukes ved evaluering av matematisk forventning, prediktiv verdi og andre egenskaper ved bruk av konfidensintervaller, for å teste hypoteser om verdiene til matematiske forventninger,ter,
Fisher-fordelingen er fordelingen av en tilfeldig variabel
Fisher-fordelingen brukes til å teste hypoteser om modellens tilstrekkelighet i regresjonsanalyse, om varianslikhet og i andre problemer med anvendt statistikk.
18Lineær regresjon er et statistisk verktøy som brukes til å forutsi fremtidige priser fra tidligere data og brukes ofte til å bestemme når prisene er overopphetet. Minste kvadraters metode brukes til å tegne den "best passende" rette linjen gjennom en rekke prisverdipoeng. Prispunktene som brukes som input kan være en av følgende: åpen, lukk, høy, lav,
17. En todimensjonal tilfeldig variabel er et ordnet sett med to tilfeldige variabler eller .
Eksempel: To terninger kastes. - antall poeng kastet på henholdsvis første og andre terning
En universell måte å spesifisere fordelingsloven til en todimensjonal tilfeldig variabel er fordelingsfunksjonen.
15.m.o Diskrete tilfeldige variabler
Eiendommer:
1) M(C) = C, C- konstant;
2) M(CX) = CM(X);
3) M(x1 + x2) = M(x1) + M(x2), hvor x1, x2- uavhengige tilfeldige variabler;
4) M(x 1 x 2) = M(x1)M(x2).
Den matematiske forventningen til summen av tilfeldige variabler er lik summen av deres matematiske forventninger, dvs.
Den matematiske forventningen til forskjellen av tilfeldige variabler er lik forskjellen av deres matematiske forventninger, dvs.
Den matematiske forventningen til produktet av tilfeldige variabler er lik produktet av deres matematiske forventninger, dvs.
Hvis alle verdiene til en tilfeldig variabel økes (reduseres) med samme tall C, vil dens matematiske forventning øke (reduseres) med samme tall
14. Eksponentiell(eksponentiell)distribusjonsloven X har en eksponentiell (eksponentiell) distribusjonslov med parameter λ >0 hvis sannsynlighetstettheten har formen:
![]()
Forventet verdi: .
spredning: .
Den eksponentielle fordelingsloven spiller en viktig rolle i køteori og reliabilitetsteori.
13. Normalfordelingsloven er karakterisert ved en feilrate a (t) eller en feilsannsynlighetstetthet f (t) av formen:
 , (5.36)
, (5.36)
hvor σ er standardavviket til SW x;
m x– matematisk forventning til CB x. Denne parameteren blir ofte referert til som spredningssenteret eller den mest sannsynlige verdien av SW. X.
x- en tilfeldig variabel, som kan tas som tid, strømverdi, elektrisk spenningsverdi og andre argumenter.
Normalloven er en to-parameter lov, som du trenger å vite m x og σ.
Normalfordelingen (gaussisk distribusjon) brukes til å vurdere påliteligheten til produkter som påvirkes av en rekke tilfeldige faktorer, som hver har liten effekt på den resulterende effekten.
12. Ensartet distribusjonslov. Kontinuerlig tilfeldig variabel X har en enhetlig distribusjonslov på segmentet [ en, b], hvis sannsynlighetstettheten er konstant på dette segmentet og er lik null utenfor det, dvs.

Betegnelse: .
Forventet verdi: .
spredning: .
Tilfeldig verdi X, fordelt jevnt på et segment kalles tilfeldig tall fra 0 til 1. Det tjener som kildemateriale for å få tilfeldige variabler med en hvilken som helst distribusjonslov. Den enhetlige fordelingsloven brukes i analyse av avrundingsfeil i tallberegninger, i en rekke køproblemer, i statistisk modellering av observasjoner underlagt en gitt fordeling.
11. Definisjon. Distribusjonstetthet sannsynligheter for en kontinuerlig tilfeldig variabel X kalles en funksjon f(x) er den første deriverte av fordelingsfunksjonen F(x).
Distribusjonstetthet kalles også differensial funksjon. For å beskrive en diskret tilfeldig variabel er distribusjonstettheten uakseptabel.
Betydningen av distribusjonstettheten er at den viser hvor ofte en tilfeldig variabel X vises i et eller annet område av punktet X når du gjentar eksperimenter.
Etter å ha introdusert fordelingsfunksjonene og distribusjonstettheten, kan vi gi følgende definisjon av en kontinuerlig tilfeldig variabel.
10. Sannsynlighetstetthet, stil en tilfeldig variabel x, er en funksjon p(x) slik at 
og for enhver a< b вероятность события a < x < b равна
.
Hvis p(x) er kontinuerlig, så for tilstrekkelig liten ∆x sannsynligheten for ulikheten x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
og, hvis F(x) er differensierbar, da ![]()
Forelesning 13
La den statistiske fordelingen av frekvensene til den kvantitative egenskapen X være kjent. La oss betegne med antall observasjoner der verdien av egenskapen mindre enn x ble observert, og med n det totale antallet observasjoner. Åpenbart, den relative frekvensen av hendelsen X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Empirisk distribusjonsfunksjon(sampling distribusjonsfunksjon) er en funksjon som bestemmer for hver verdi x den relative frekvensen av hendelsen X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
I motsetning til den empiriske fordelingsfunksjonen til utvalget, kalles populasjonsfordelingsfunksjonen teoretisk distribusjonsfunksjon. Forskjellen mellom disse funksjonene er at den teoretiske funksjonen definerer sannsynlighet hendelser X< x, тогда как эмпирическая – relativ frekvens samme hendelse.
Når n vokser, vil den relative frekvensen av hendelsen X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Egenskaper til den empiriske distribusjonsfunksjonen:
1) Verdiene til den empiriske funksjonen tilhører segmentet
2) - ikke-minkende funksjon
3) Hvis - det minste alternativet, så = 0 ved , hvis - det største alternativet, så =1 ved .
Den empiriske fordelingsfunksjonen til utvalget tjener til å estimere den teoretiske fordelingsfunksjonen til populasjonen.
Eksempel. La oss bygge en empirisk funksjon i henhold til fordelingen av utvalget:
| Alternativer | |||
| Frekvenser |
La oss finne prøvestørrelsen: 12+18+30=60. Det minste alternativet er 2, så =0 for x £ 2. Verdien av x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Dermed har den ønskede empiriske funksjonen formen:
De viktigste egenskapene til statistiske estimater
La det være nødvendig å studere noen kvantitative attributter for den generelle befolkningen. La oss anta at det ut fra teoretiske betraktninger var mulig å fastslå det hvilken distribusjonen har et attributt, og det er nødvendig å evaluere parameterne som den bestemmes av. For eksempel, hvis egenskapen som studeres er normalfordelt i den generelle befolkningen, er det nødvendig å estimere den matematiske forventningen og standardavviket; hvis attributtet har en Poisson-fordeling, er det nødvendig å estimere parameteren l.
Vanligvis er bare prøvedata tilgjengelig, for eksempel egenskapsverdier fra n uavhengige observasjoner. Tatt i betraktning som uavhengige tilfeldige variabler, kan vi si det å finne et statistisk estimat av en ukjent parameter av en teoretisk fordeling betyr å finne en funksjon av de observerte tilfeldige variablene, som gir en tilnærmet verdi av den estimerte parameteren. For eksempel, for å estimere den matematiske forventningen til en normalfordeling, spilles rollen til en funksjon av det aritmetiske gjennomsnittet
For at statistiske estimater skal gi korrekte tilnærminger av de estimerte parametrene, må de tilfredsstille visse krav, hvorav de viktigste er kravene upartiskhet og soliditet estimater.
La være et statistisk estimat av den ukjente parameteren til den teoretiske fordelingen. La anslaget bli funnet basert på et utvalg av størrelse n. La oss gjenta eksperimentet, dvs. vi trekker ut et annet utvalg av samme størrelse fra den generelle populasjonen, og basert på dataene får vi et annet estimat på . Ved å gjenta eksperimentet mange ganger får vi forskjellige tall. Poengsummen kan betraktes som en tilfeldig variabel og tallene som mulige verdier.
Hvis estimatet gir en tilnærming i overflod, dvs. hvert tall er større enn den sanne verdien, og som en konsekvens er den matematiske forventningen (middelverdien) til den tilfeldige variabelen større enn:. Tilsvarende, hvis den evaluerer med en ulempe, deretter .
Dermed vil bruken av et statistisk estimat, hvis matematiske forventning ikke er lik den estimerte parameteren, føre til systematiske (ett tegn) feil. Hvis tvert imot, så garanterer dette mot systematiske feil.
objektiv kalt et statistisk estimat, hvis matematiske forventning er lik den estimerte parameteren for en hvilken som helst prøvestørrelse.
Fordrevet kalles et estimat som ikke tilfredsstiller denne betingelsen.
Anslagets objektivitet garanterer ennå ikke en god tilnærming for den estimerte parameteren, siden de mulige verdiene kan være veldig spredt rundt middelverdien, dvs. variansen kan være betydelig. I dette tilfellet kan estimatet funnet fra dataene til en prøve, for eksempel, vise seg å være betydelig fjernt fra gjennomsnittsverdien , og dermed fra selve den estimerte parameteren.
effektiv kalles et statistisk estimat som for en gitt utvalgsstørrelse n har minst mulig variasjon .
Når man vurderer prøver av et stort volum, kreves statistiske estimater soliditet .
Rik kalles et statistisk estimat, som, som n®¥, tenderer i sannsynlighet til den estimerte parameteren. For eksempel, hvis variansen til en objektiv estimator har en tendens til null som n®¥, så viser en slik estimator seg også å være konsistent.
Bestemmelse av den empiriske fordelingsfunksjonen
La $X$ være en tilfeldig variabel. $F(x)$ - distribusjonsfunksjonen til den gitte tilfeldige variabelen. Vi vil utføre $n$ eksperimenter på en gitt tilfeldig variabel under de samme uavhengige betingelsene. I dette tilfellet får vi en sekvens av verdier $x_1,\ x_2\ $, ... ,$\ x_n$, som kalles en prøve.
Definisjon 1
Hver verdi av $x_i$ ($i=1,2\ $, ... ,$ \ n$) kalles en variant.
Et av estimatene for den teoretiske fordelingsfunksjonen er den empiriske fordelingsfunksjonen.
Definisjon 3
Den empiriske distribusjonsfunksjonen $F_n(x)$ er funksjonen som bestemmer for hver verdi $x$ den relative frekvensen av hendelsen $X \
der $n_x$ er antallet alternativer mindre enn $x$, er $n$ prøvestørrelsen.
Forskjellen mellom en empirisk funksjon og en teoretisk er at den teoretiske funksjonen bestemmer sannsynligheten for hendelsen $X
Egenskaper til den empiriske distribusjonsfunksjonen
La oss nå vurdere flere grunnleggende egenskaper ved fordelingsfunksjonen.
Området til funksjonen $F_n\left(x\right)$ er segmentet $$.
$F_n\left(x\right)$ er en ikke-minskende funksjon.
$F_n\left(x\right)$ er en venstre kontinuerlig funksjon.
$F_n\left(x\right)$ er en stykkevis konstant funksjon og øker bare ved verdipunkter for den tilfeldige variabelen $X$
La $X_1$ være den minste, og $X_n$ være den største varianten. Deretter $F_n\left(x\right)=0$ for $(x\le X)_1$ og $F_n\left(x\right)=1$ for $x\ge X_n$.
La oss introdusere et teorem som forbinder de teoretiske og empiriske funksjonene.
Teorem 1
La $F_n\left(x\right)$ være den empiriske fordelingsfunksjonen og $F\left(x\right)$ være den teoretiske fordelingsfunksjonen til det generelle utvalget. Da gjelder likestillingen:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Eksempler på problemer for å finne den empiriske fordelingsfunksjonen
Eksempel 1
La prøvefordelingen ha følgende data, registrert ved hjelp av en tabell:
Bilde 1.
Finn prøvestørrelsen, komponer en empirisk distribusjonsfunksjon og plott den.
Eksempelstørrelse: $n=5+10+15+20=50$.
Ved egenskap 5 har vi det for $x\le 1$ $F_n\left(x\right)=0$, og for $x>4$ $F_n\left(x\right)=1$.
$x verdi
$x verdi
$x verdi
Dermed får vi:

Figur 2.

Figur 3
Eksempel 2
Fra byene i den sentrale delen av Russland ble 20 byer tilfeldig valgt, for hvilke følgende data om priser i offentlig transport ble innhentet: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15 , 14, 15, 13, 13, 12, 12, 15, 14, 14.
Komponer en empirisk distribusjonsfunksjon av denne prøven og bygg grafen.
Vi skriver prøveverdiene i stigende rekkefølge og beregner frekvensen til hver verdi. Vi får følgende tabell:
Figur 4
Prøvestørrelse: $n=20$.
Ved egenskap 5 har vi det for $x\le 12$ $F_n\left(x\right)=0$, og for $x>15$ $F_n\left(x\right)=1$.
$x verdi
$x verdi
$x verdi
Dermed får vi:

Figur 5
La oss plotte den empiriske fordelingen:
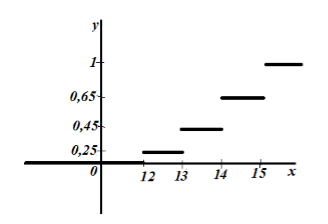
Figur 6
Originalitet: $92,12\%$.
Bestemmelse av den empiriske fordelingsfunksjonen
La $X$ være en tilfeldig variabel. $F(x)$ - distribusjonsfunksjonen til den gitte tilfeldige variabelen. Vi vil utføre $n$ eksperimenter på en gitt tilfeldig variabel under de samme uavhengige betingelsene. I dette tilfellet får vi en sekvens av verdier $x_1,\ x_2\ $, ... ,$\ x_n$, som kalles en prøve.
Definisjon 1
Hver verdi av $x_i$ ($i=1,2\ $, ... ,$ \ n$) kalles en variant.
Et av estimatene for den teoretiske fordelingsfunksjonen er den empiriske fordelingsfunksjonen.
Definisjon 3
Den empiriske distribusjonsfunksjonen $F_n(x)$ er funksjonen som bestemmer for hver verdi $x$ den relative frekvensen av hendelsen $X \
der $n_x$ er antallet alternativer mindre enn $x$, er $n$ prøvestørrelsen.
Forskjellen mellom en empirisk funksjon og en teoretisk er at den teoretiske funksjonen bestemmer sannsynligheten for hendelsen $X
Egenskaper til den empiriske distribusjonsfunksjonen
La oss nå vurdere flere grunnleggende egenskaper ved fordelingsfunksjonen.
Området til funksjonen $F_n\left(x\right)$ er segmentet $$.
$F_n\left(x\right)$ er en ikke-minskende funksjon.
$F_n\left(x\right)$ er en venstre kontinuerlig funksjon.
$F_n\left(x\right)$ er en stykkevis konstant funksjon og øker bare ved verdipunkter for den tilfeldige variabelen $X$
La $X_1$ være den minste, og $X_n$ være den største varianten. Deretter $F_n\left(x\right)=0$ for $(x\le X)_1$ og $F_n\left(x\right)=1$ for $x\ge X_n$.
La oss introdusere et teorem som forbinder de teoretiske og empiriske funksjonene.
Teorem 1
La $F_n\left(x\right)$ være den empiriske fordelingsfunksjonen og $F\left(x\right)$ være den teoretiske fordelingsfunksjonen til det generelle utvalget. Da gjelder likestillingen:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Eksempler på problemer for å finne den empiriske fordelingsfunksjonen
Eksempel 1
La prøvefordelingen ha følgende data, registrert ved hjelp av en tabell:
Bilde 1.
Finn prøvestørrelsen, komponer en empirisk distribusjonsfunksjon og plott den.
Eksempelstørrelse: $n=5+10+15+20=50$.
Ved egenskap 5 har vi det for $x\le 1$ $F_n\left(x\right)=0$, og for $x>4$ $F_n\left(x\right)=1$.
$x verdi
$x verdi
$x verdi
Dermed får vi:
Figur 2.
Figur 3
Eksempel 2
Fra byene i den sentrale delen av Russland ble 20 byer tilfeldig valgt, for hvilke følgende data om priser i offentlig transport ble innhentet: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15 , 14, 15, 13, 13, 12, 12, 15, 14, 14.
Komponer en empirisk distribusjonsfunksjon av denne prøven og bygg grafen.
Vi skriver prøveverdiene i stigende rekkefølge og beregner frekvensen til hver verdi. Vi får følgende tabell:
Figur 4
Prøvestørrelse: $n=20$.
Ved egenskap 5 har vi det for $x\le 12$ $F_n\left(x\right)=0$, og for $x>15$ $F_n\left(x\right)=1$.
$x verdi
$x verdi
$x verdi
Dermed får vi:
Figur 5
La oss plotte den empiriske fordelingen:
Figur 6
Originalitet: $92,12\%$.


